
I am a fourth-year Ph.D. student at School of Mathematical Sciences, Shanghai Jiao Tong University (SJTU). Before that, I received my Bachelor’s degree from Zhiyuan College of SJTU in 2021.
I am currently advised by Prof. Zhiqin Xu. My research interests are in understanding deep learning from the training process, loss landscape, generalization and application, and also the interpretability of large language models. If you’re interested in my research, please feel free to contact me (Wechat).
🔥 News
- 2025.07: 🎉🎉 Our project WebSailor topped GitHub trending!
- 2025.05: 🎉🎉 One paper accepted to ICML 2025 spotlight!
- 2025.02: 🎉🎉 One paper accepted to JCM (T1 journal in computational mathematics)!
- 2024.09: 🎉🎉 I won the 2024 China National Scholarship!
- 2024.09: 🎉🎉 One paper accepted to NeurIPS 2024!
- 2024.01: 🎉🎉 One paper accepted to ICLR 2024!
- 2024.01: 🎉🎉 One paper accepted to TPAMI!
📝 Publications
* denotes equal contribution, † denotes corresponding author, see the full list in Google Scholar.
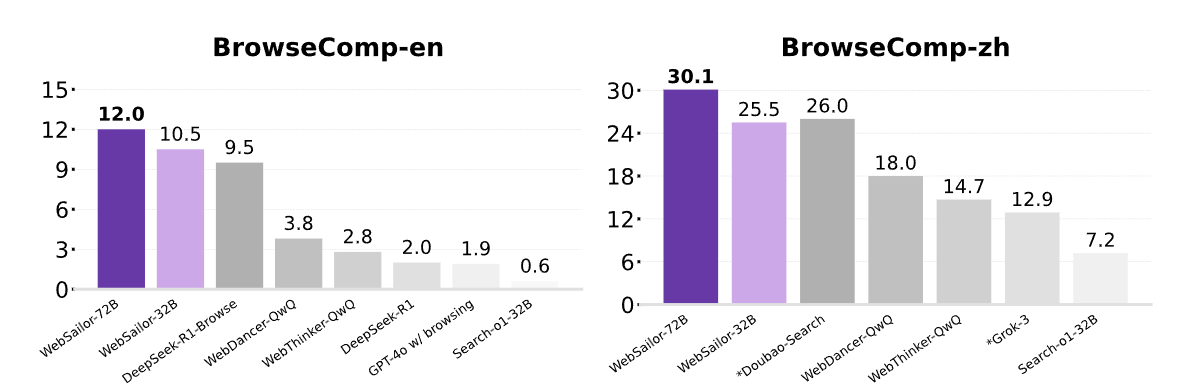
WebSailor: Navigating Super-human Reasoning for Web Agent
Kuan Li*, Zhongwang Zhang*, Huifeng Yin*†, Liwen Zhang*, Litu Ou*, Jialong Wu, Wenbiao Yin, Baixuan Li, Zhengwei Tao, Xinyu Wang, Weizhou Shen, Junkai Zhang, Dingchu Zhang, Xixi Wu, Yong Jiang†, Ming Yan, Pengjun Xie, Fei Huang, Jingren Zhou
- This paper presents WebSailor, a framework for training superhuman web agents that excel at complex reasoning tasks. Key innovations include: (1) SailorFog-QA, a synthetic dataset with high-uncertainty questions generated via graph-based sampling and obfuscation; (2) Reconstructed reasoning trajectories that distill expert solutions into concise action plans; and (3) Duplicating Sampling Policy Optimization (DUPO), an RL method that accelerates training for long-horizon tasks. WebSailor models outperform existing open-source agents and rival proprietary systems on highly challenging benchmarks like BrowseComp.

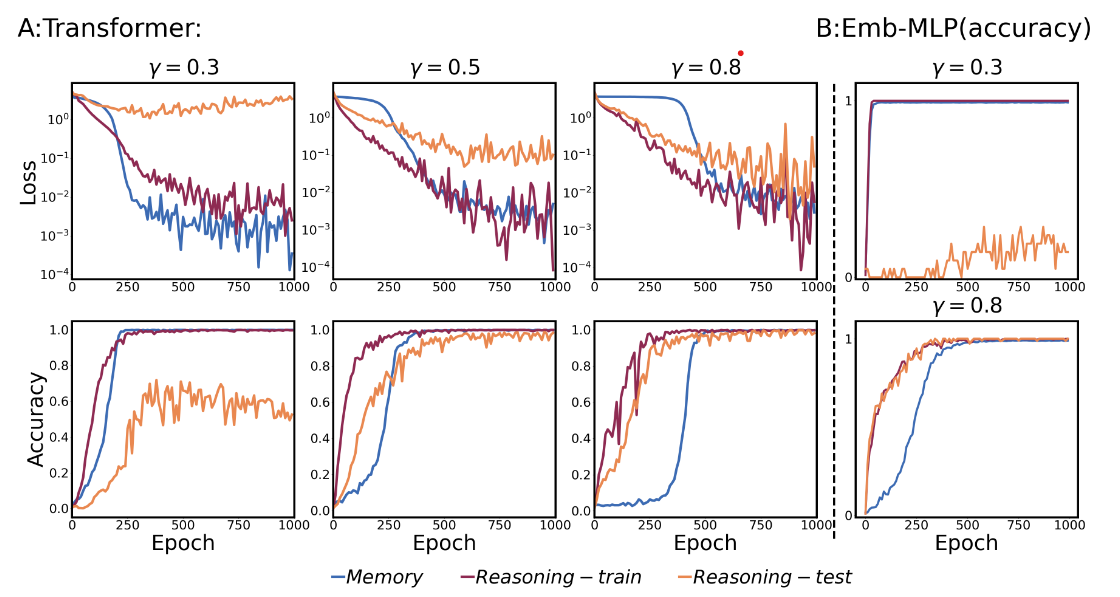
An Analysis for Reasoning Bias of Language Models with Small Initialization
Junjie Yao, Zhongwang Zhang†, Zhi-Qin John Xu†
- This paper reveals how initialization scales shape transformer-based models’ task preferences: smaller scales induce reasoning bias through structured embeddings, while larger scales promote memorization. We attribute this to differential label-driven embedding dynamics, validated theoretically and empirically across architectures.
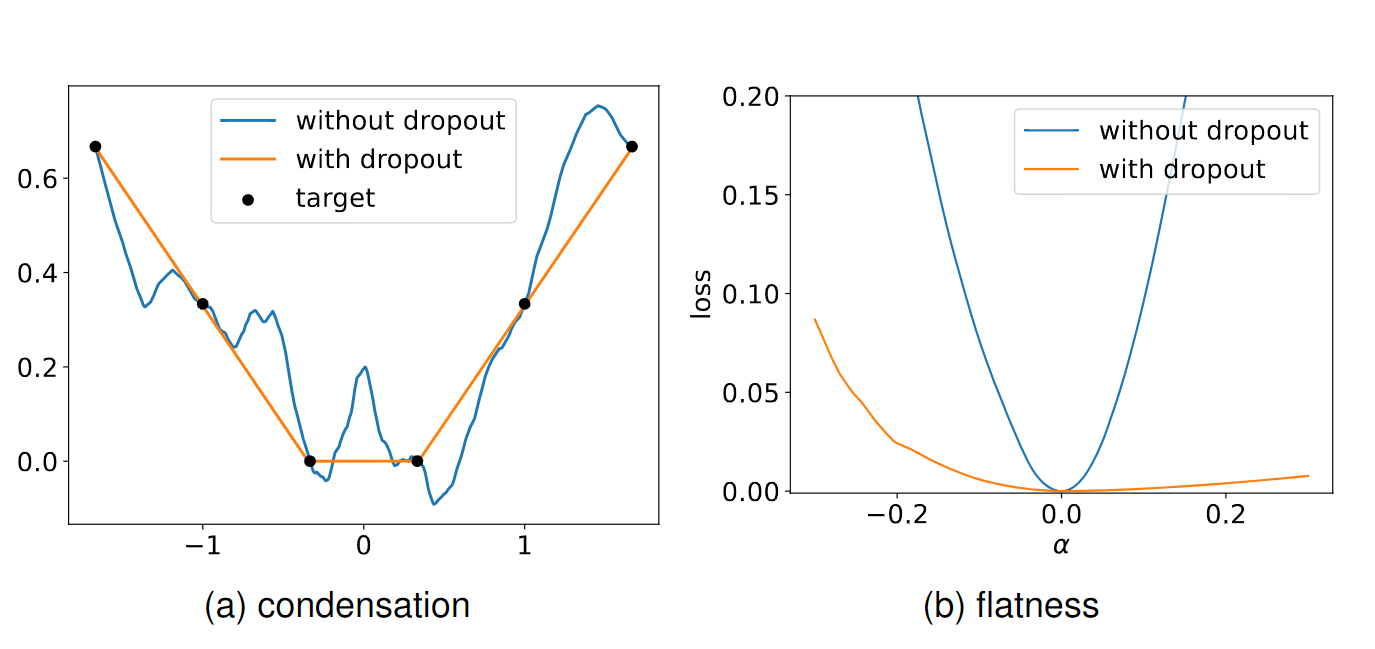
Implicit Regularization of Dropout
Zhongwang Zhang, Zhi-Qin John Xu†
- This paper proposes a theoretical derivation of an implicit regularization of dropout, which is validated through experiments and numerically studied to understand how dropout improves generalization during neural network training by promoting weight condensation and finding flatter solutions.
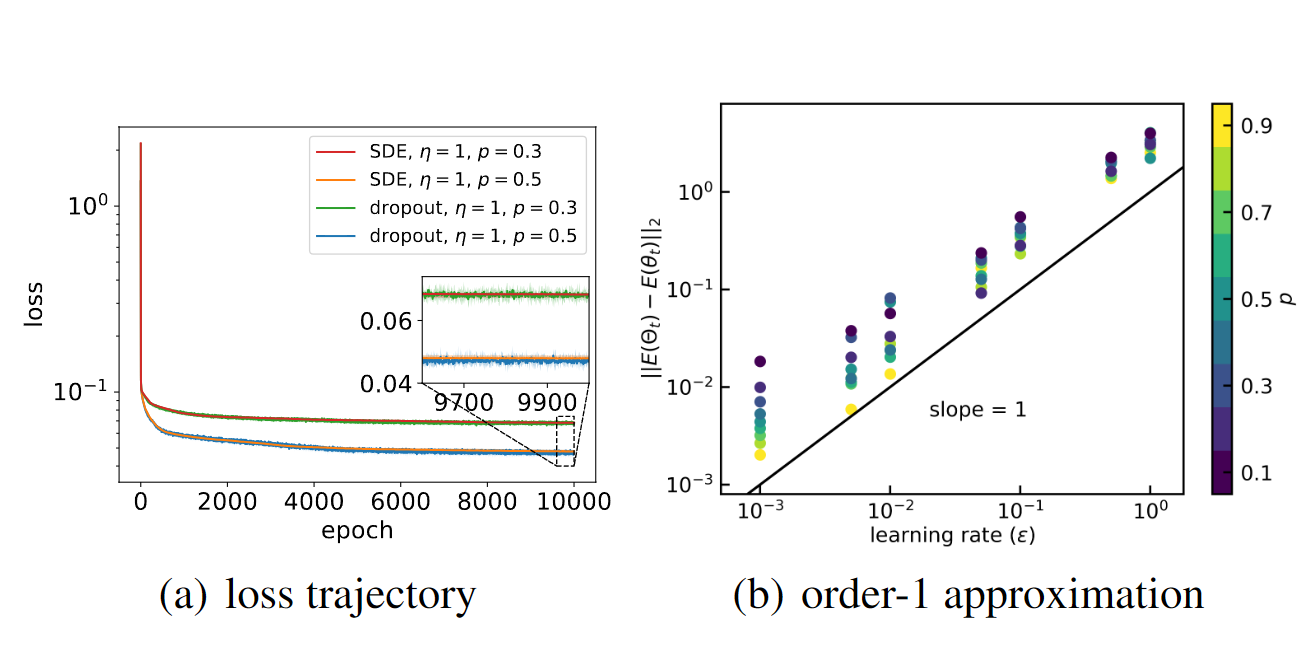
Stochastic Modified Equations and Dynamics of Dropout Algorithm
Zhongwang Zhang, Yuqing Li†, Tao Luo†, Zhi-Qin John Xu†
- This paper proposes a rigorous theoretical derivation of the stochastic modified equations to approximate the discrete iterative process of dropout and empirically investigates the mechanisms by which dropout facilitates the identification of flatter minima through intuitive approximations exploiting the structural analogies in the Hessian of loss landscape and the covariance of dropout.
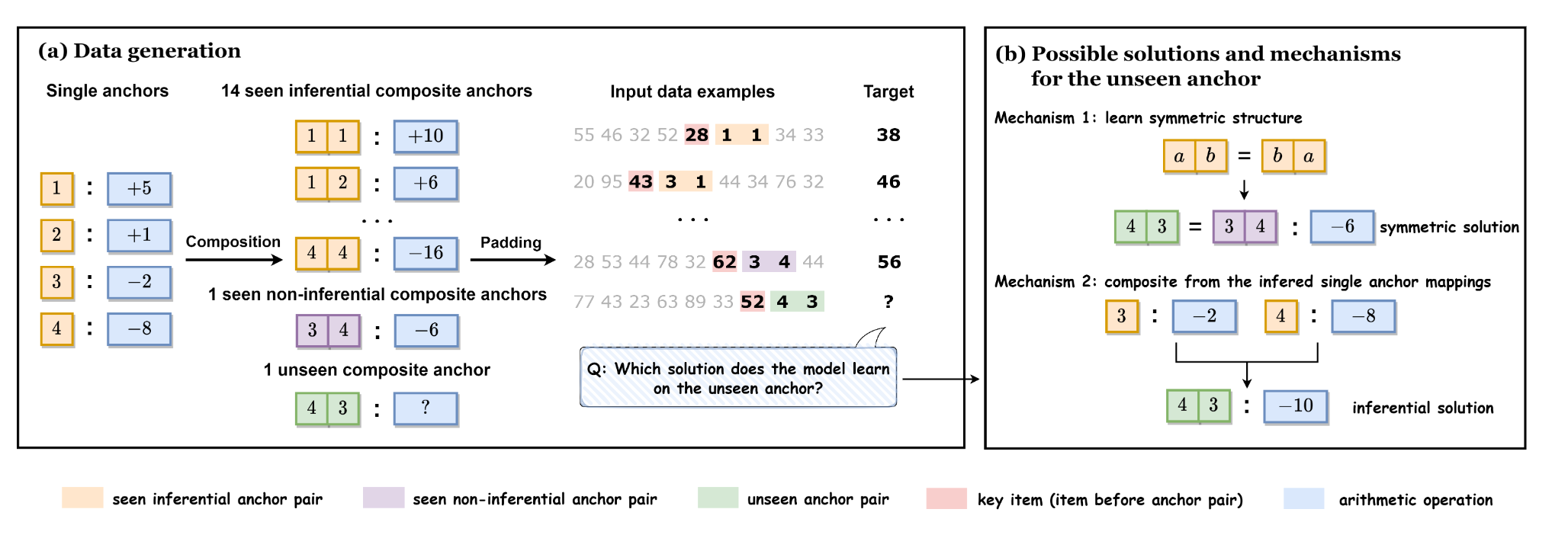
Zhongwang Zhang, Pengxiao Lin, Zhiwei Wang, Yaoyu Zhang, Zhi-Qin John Xu†
- This paper investigates the mechanisms of how transformers behave on unseen compositional tasks using anchor functions, revealing that the parameter initialization scale determines whether the model learns inferential solutions that capture the underlying compositional primitives or symmetric solutions that simply memorize mappings, and provides insights into the role of initialization scale in shaping the type of solution learned and their ability to generalize compositional functions.
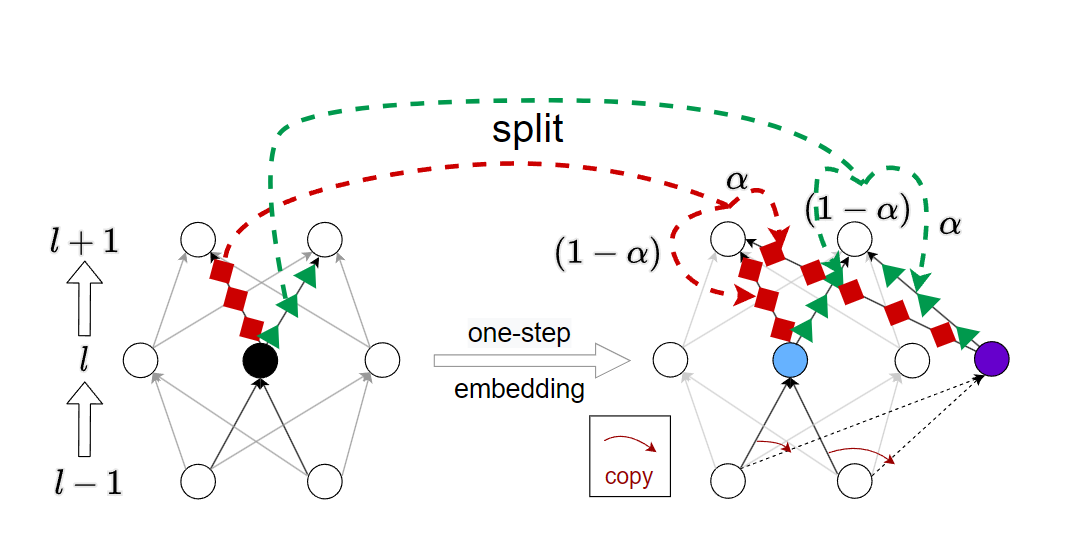
Embedding principle of loss landscape of deep neural networks
Yaoyu Zhang†, Zhongwang Zhang, Tao Luo, Zhi-Qin John Xu†
- This paper proves an embedding principle that the loss landscape of a deep neural network (DNN) contains all the critical points of narrower DNNs, and proposes a critical embedding such that any critical point of a narrower DNN can be embedded to a critical point/affine subspace of the target DNN with higher degeneracy while preserving the DNN output function, providing a new perspective to study the general easy optimization of wide DNNs and unraveling a potential implicit low-complexity regularization during training.
🎖 Honors and Awards –>
- 2024.09 I won the 2024 China National Scholarship!
📖 Educations
- 2021.09 - now, Ph.D., School of Mathematical Sciences, Shanghai Jiao Tong University.
- 2017.09 - 2021.06, Undergraduate, Zhiyuan College, Shanghai Jiao Tong University.
💻 Internships
- 2025.04 - now, Tongyi Lab, Alibaba Group.
- 2024.04 - 2025.04, Institute for Advanced Algorithms Research.